Switching to Vodafone Uncovered a Bug
Recently I’ve switched to Vodafone for all my cellular needs, in a twisted turn of events this uncovered a goroutine leak in miekg/dns.
First some background on the setup I have at home (where this first showed up). I have your run-of-the-mill LAN + Wifi and a Raspberry Pi running CoreDNS for my DNS (proxy) needs. This CoreDNS instance forwards all DNS traffic to https://dns.google.com which uses a non-standard DNS protocol implemented as JSON over HTTPS. I use this so that my DNS traffic is encrypted. Note that CoreDNS makes heavy use of miekg/dns.
So one day I am doing a journalctl -fu coredns on the Pi and seeing NAPTR queries show up (and
erroring):
Nov 14 08:10:40 raspberrypi coredns[7925]: 192.168.1.124 - [14/Nov/2017:08:10:40 +0000] "NAPTR IN mplus.ims.vodafone.com. udp 40 false 512" SERVFAIL qr,rd 40 79.988891ms
Nov 14 08:10:40 raspberrypi coredns[7925]: 14/Nov/2017:08:10:40 +0000 [ERROR 0 mplus.ims.vodafone.com. NAPTR] unreachable backend: no upstream host
Just seeing NAPTR queries in the wild was odd (they’re not that common). Seeing the error was weird,
but I shrugged it off as something Vodafone had been using but turned down or something. (The no upstream host is misleading here).
More than a week later I started working on getting my Grafana instance back in order and while fidding with it I saw this enourmous pile of goroutines being used on the Pi.
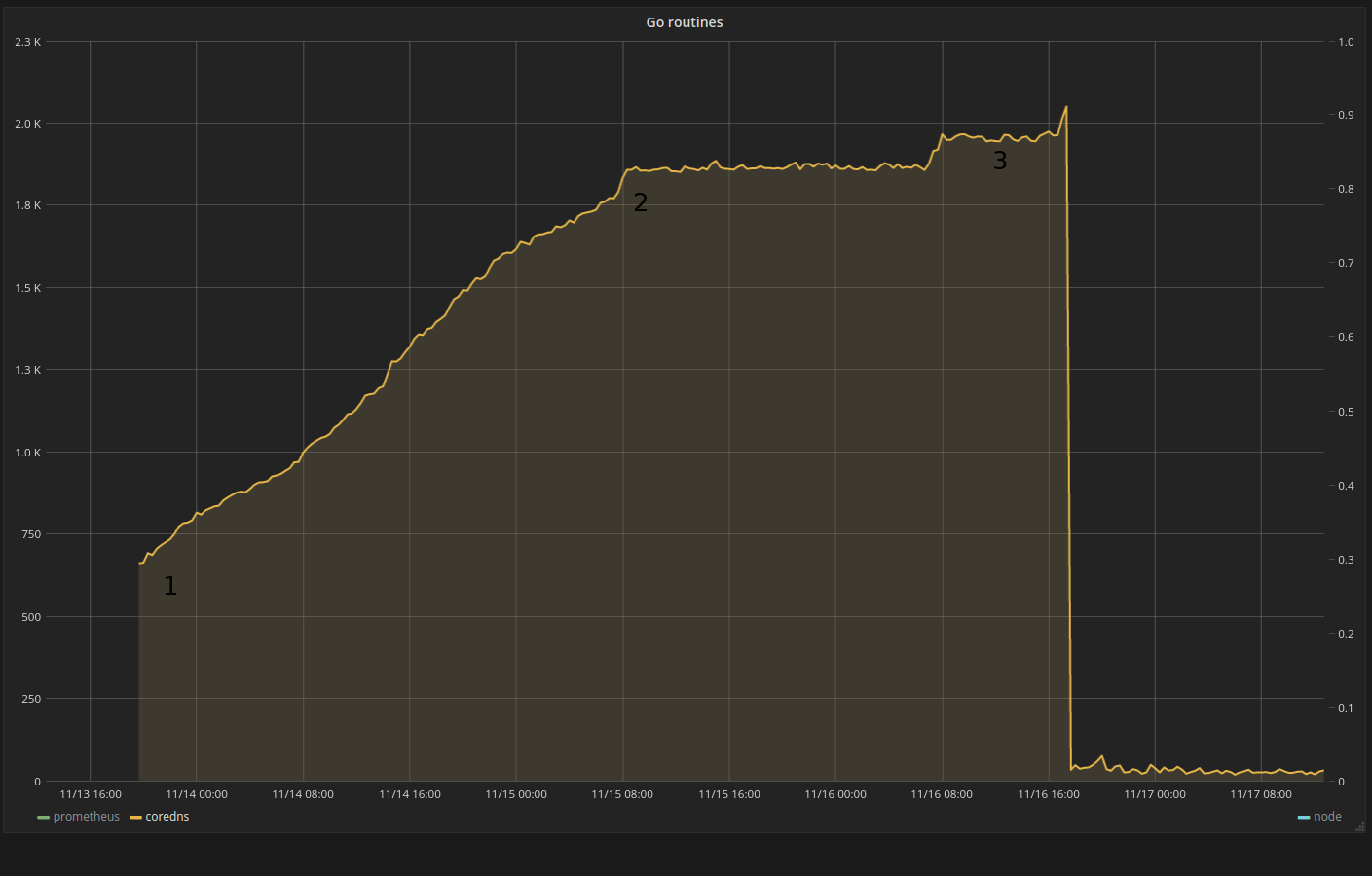
In the above image, number:
- (1) starting monitoring and seeing an increase
- (2) I believe this is my wife swapping her sim for a Vodafone one
- (3) The spike to the right is when started to figure out things
The large drop is when I restarted CoreDNS to enable the pprof
plugin, then the small increase when I really found the culprit and used dig a lot.
I filled issue 1233 and issue 1235 not knowing yet it was a miekg/dns bug.
I also have another instance, running as an auth server, which didn’t have this issue (pfew!), which narrowed down what plugins could be responsible for this.
Debug⌗
To start debugging in earnest I restarted CoreDNS with the pprof
plugin and use the pprof endpoint: localhost:6053/debug/pprof/goroutine?debug=1 to dump the
running goroutines.
At the top it says something in the lexer is lingering. I did not believe immediately that miekg/dns was the culprit here, even though this clearly says so, I opened miekg/dns/issues/568 in any case.
goroutine profile: total 27
7 @ 0x3e6c8 0x3e790 0x14124 0x13ea8 0x224060 0x6fd2c
# 0x22405f github.com/miekg/dns.zlexer+0x347 /home/miek/g/src/github.com/miekg/dns/scan.go:602
2 @ 0x3e6c8 0x39a5c 0x38edc 0xa420c 0xa4280 0xa4e78 0x135948 0x145e04 0x1e48a0 0x1e4d14 0x1e7cd0 0x302a58 0xf8530 0xf868c 0x30337c 0x6fd2c
# 0x38edb internal/poll.runtime_pollWait+0x43 /home/miek/upstream/go/src/runtime/netpoll.go:173
# 0xa420b internal/poll.(*pollDesc).wait+0x8b /home/miek/upstream/go/src/internal/poll/fd_poll_runtime.go:85
During this debugging I happen to notice those NAPTR requests again. And every time one was done an
extra scan.go:602 goroutine showed up. From the logs I grabbed the domain name that was being
asked and replayed with dig mplus.ims.vodafone.com. NAPTR. Sure enough the goroutine count
increased by 3 (dig will retry 3 times by default). Bypassing CoreDNS and issuing this request
against 8.8.8.8 would yield the correct results.
So what is wrong here?
JSON⌗
By using dns.google.com everything needs to be put in a JSON payload. Going to:
https://dns.google.com/resolve?name=mplus.ims.vodafone.com.&type=NAPTR, it shows:
{"Status": 0,"TC": false,"RD": true,"RA": true,"AD": false,"CD": false,"Question":[ {"name":
"mplus.ims.vodafone.com.","type": 35}],"Answer":[ {"name": "mplus.ims.vodafone.com.","type":
35,"TTL": 1521,"data": "10 100 S SIP+D2T _sip._tcp.mplus.ims.vodafone.com."},{"name":
"mplus.ims.vodafone.com.","type": 35,"TTL": 1521,"data": "10 100 S SIPS+D2T
_sips._tcp.mplus.ims.vodafone.com."},{"name": "mplus.ims.vodafone.com.","type": 35,"TTL":
1521,"data": "10 100 S SIP+D2U _sip._udp.mplus.ims.vodafone.com."}]}
Looks legit? The problem here is that because all the RDATA is put in the data element, it strips
quotes from the text presentation that are mandatory for NAPTR records, i.e.:
"data": "10 100 S SIP+D2T _sip._tcp.mplus.ims.vodafone.com."
Should have been encoded as:
"data": "10 100 \"S\" \"SIP+D2T\" \"\" _sip._tcp.mplus.ims.vodafone.com."
dns.NewRR⌗
In CoreDNS this JSON is parsed in plugin/proxy/google_rr.go which calls
dns.NewRR. That code is sits in
scan.go. The gist of the code is that to spawn
a lexer goroutine that sends tokens down on a channel that are consumed by a “grammar” like parser to
make sense of the string.
A successful parse means the lexer see an EOF “error”, drops out of the for-loop and exits the function and ends the goroutine.
A non successful parse that stops midway however is an entirely different story, because of the
missing quotes around S in the returned NAPTR record, we do bail out early, but this means
- the zlexer function does not see an EOF
- it consumes the next token and then sits idling, trying to send it on the channel
- the reader of the channel is gone, because we’ve stopped parsing
Result: a leaked goroutine.
Fix⌗
The fix was to make sure the zlexer goroutine would exit even when the higher layer saw an error. In this PR implement with a context that gets canceled which triggers the exit from the zlexer function. Is also adds a test that checks for goroutine leaks.
Morale of the story? Don’t switch providers. Dogfood your own stuff and always make sure you
know how to stop
a goroutine.
Fun fact: this code was committed on December 14 2011!